Carsten Stoll
I am a Research Scientist at Meta, developing next-generation digital humans.
I earned my PhD in Computer Graphics and Computer Vision from the Max-Planck Institute for Informatics with Prof. Christian Theobalt. I also led the Optical Performance Capture group at the Max-Planck Center for Visual Computing and Communication and spent a year as a visiting researcher at Weta Digital.
I cofounded The Captury, a company focused on real-time markerless motion capture, and then joined Facebook Reality Labs to work on full-body virtual humans. In 2020 I joined Epic Games to work on next-generation MetaHumans and real-time machine learning methods. In 2025 I rejoined Meta to advance the state of the art in photorealistic human avatars.
My research spans computer graphics, geometric modeling, animation, and computer vision. My goal is to create and control fully photorealistic, believable digital human avatars.

Expertise
Recent
- Apr 2026 Large-scale Codec Avatars — full-body avatar model generalizing to world-scale populations, preprint released
- Nov 2025 MHR open-sourced — Momentum Human Rig released as an open-source parametric body model
- Jun 2025 MetaHuman Bodies ships with Unreal Engine 5.6 — parametric body model now available to all UE developers
- Jun 2025 ML Deformer featured in the Witcher 4 tech demo at Unreal Fest 2025
Projects

Metahuman Bodies
At Epic Games I led the research and technical development of a parametric body model for MetaHumans, released with Unreal Engine 5.6. While prior versions of MetaHumans were based on discrete body types, the parametric model allows fine-grained direct and measurement-based editing of body shapes.
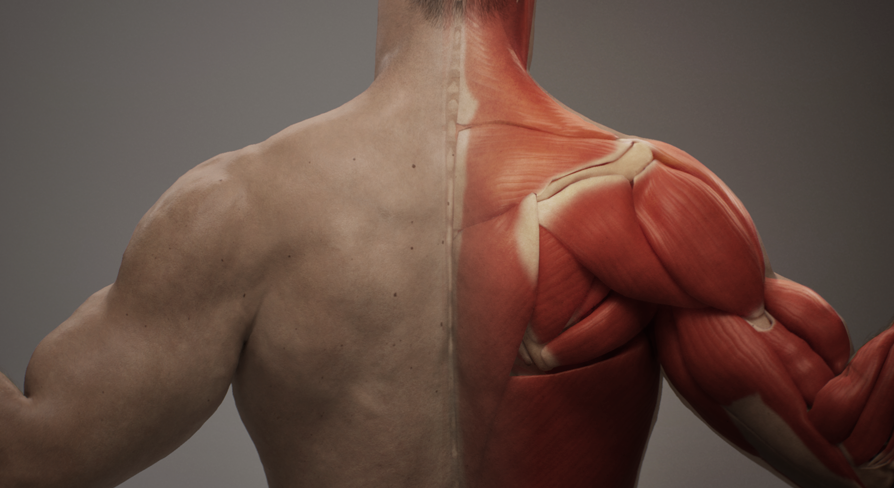
ML Deformer
I developed the ML model driving Unreal Engine's ML Deformer plugin, which trains a neural network to approximate full muscle, flesh, and cloth simulation at real-time speeds. The result is high-fidelity character deformation that would be far too costly to simulate directly. ML Deformer is now widely used in game development, including the Witcher 4 tech demo shown at Unreal Fest 2025.
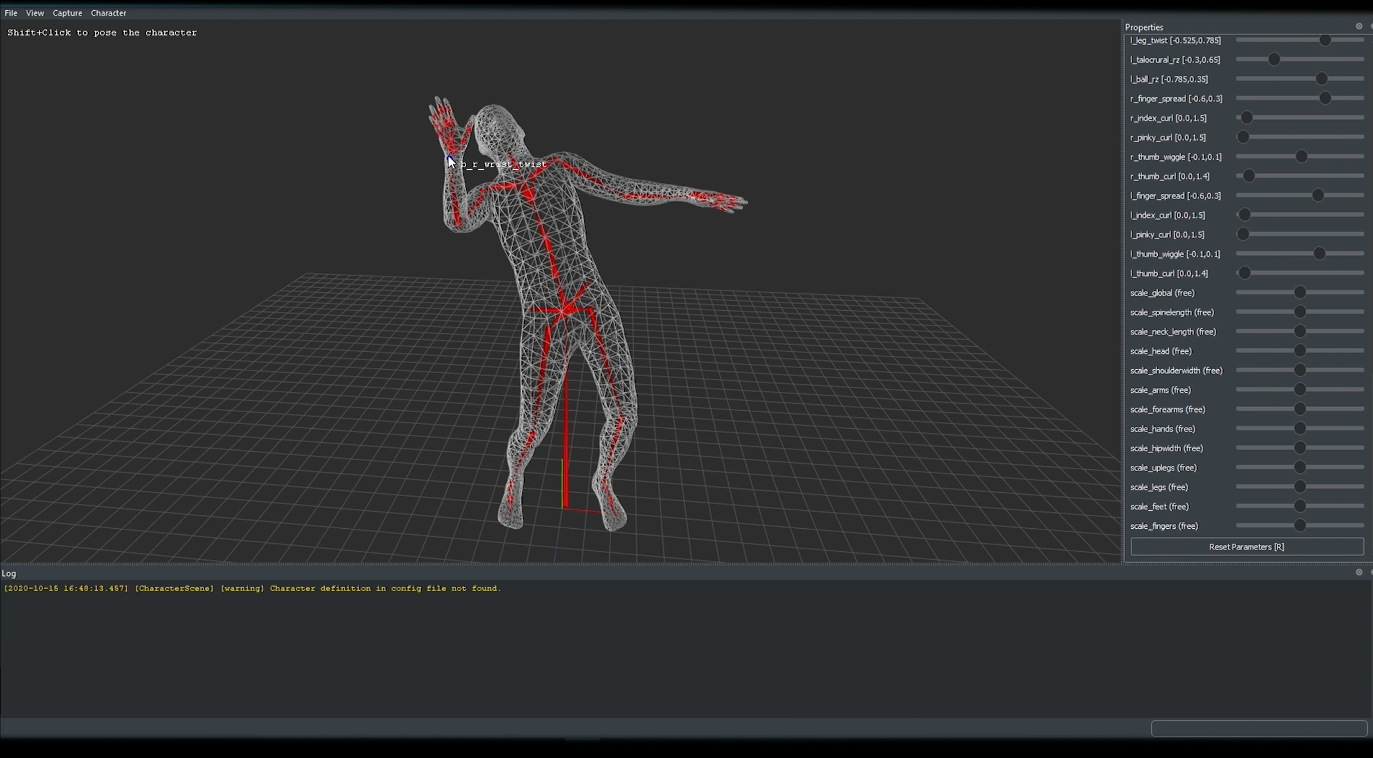
Momentum
At Facebook/Oculus Research I developed the Momentum library for human kinematics and numerical optimization, used to prototype markerless motion capture algorithms and for early versions of the Oculus VR headset upper-body tracking. We also published MHR, the Momentum Human Rig, an open-source parametric body model built on Momentum.

The Captury
I cofounded The Captury to commercialize the markerless motion capture research from my 2011 ICCV paper on the Sums of Gaussians body model. The system brought real-time, marker-free full-body capture to production environments — film sets, sports analytics, and game studios — without the suit or studio setup that traditional systems required.
Publications
2026

Large-scale Codec Avatars
arxiv, 2026
LCA is a high-fidelity, full-body 3D avatar model that generalizes to world-scale populations in a feedforward manner. Inspired by the success of large language models, we introduce a pre/post-training paradigm for 3D avatar modeling: pretraining on diverse multi-view studio data and post-training on in-the-wild images. Given a handful of images, LCA produces identity-preserving 3D avatars driven by facial expressions, full-body motion, and fine-grained hand poses.
2025

MHR: Momentum Human Rig
arxiv, 2025
MHR is a parametric human body model that combines the decoupled skeleton/shape paradigm of ATLAS with a flexible, modern rig and pose corrective system inspired by the Momentum library. It enables expressive, anatomically plausible human animation with non-linear pose correctives, and is designed for robust integration in AR/VR and graphics pipelines. MHR is available as open source.
2024
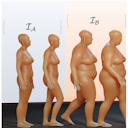
HUMOS: Human Motion Model Conditioned on Body Shape
ECCV, 2024
We introduce a generative motion model conditioned on body shape. Most existing models ignore how body proportions influence the way people move, relying on a standardized average body. Using cycle consistency, intuitive physics, and stability constraints on unpaired data, our approach generates diverse, physically plausible motions that reflect individual body characteristics.
EPOCH: Jointly Estimating the 3D Pose of Cameras and Humans
ECCV T-CAP Workshop, 2024
EPOCH is a framework for monocular 3D human pose estimation that uses the full perspective camera model instead of common weak-perspective approximations. It jointly estimates camera parameters and 3D pose through a lifter network and a regressor network, establishing an unambiguous 2D-to-3D relationship.
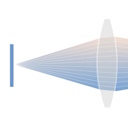
fNeRF: High Quality Radiance Fields from Practical Cameras
arxiv, 2024
Standard Neural Radiance Fields use a pinhole camera model, which bakes defocus blur into the reconstruction. We propose a modified ray casting approach that leverages the optics of real lenses with finite aperture, modeling partial occlusions more faithfully than existing approximations. This yields sharper reconstructions with up to 3 dB PSNR improvement on synthetic and real datasets.
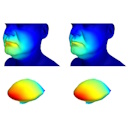
PhisaNet: Phonetically Informed Speech Animation Network
ICASSP, 2024
PhISANet leverages neural audio representations pre-trained on large speech corpora to map audio signals into animation parameters for the lower face and tongue of realistic 3D models. A CTC-based phonetic loss provides additional supervision, improving the phonetic accuracy of generated lip and tongue animation.
2023

Personalized 3D Human Pose and Shape Refinement
IEEE/CVF ICCVW, 2023
We propose a test-time optimization approach that refines 3D human pose and shape estimates for specific individuals, improving on generic feed-forward predictions. By exploiting temporal consistency and person-specific body shape priors during inference, the method adapts to individual body proportions and motion patterns without retraining.
2022
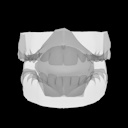
Speech Driven Tongue Animation
IEEE/CVF CVPR, 2022
Most speech-driven facial animation focuses on lip motion and neglects the inner mouth. We introduce a large-scale speech and motion capture dataset focused on tongue, jaw, and lip movement, and propose a deep learning method using self-supervised audio feature encoders. The approach generalizes well to unseen speakers and content, enabling realistic tongue animation from audio alone.
2021

ANR: Articulated Neural Rendering for Virtual Avatars
IEEE CVPR, 2021
We extend Deferred Neural Rendering to articulated human bodies, addressing challenges like mesh deformation inaccuracies and pose-dependent dynamics. ANR uses a neural shading step that explicitly accounts for geometric misalignment between a coarse mesh and the true surface. User studies show a clear preference for our approach over existing avatar creation and animation methods.
2020

TexMesh: Reconstructing Detailed Human Texture and Geometry from RGB-D Video
ECCV, 2020
TexMesh reconstructs detailed human meshes with high-resolution full-body albedo texture from RGB-D video. By leveraging the captured environment illumination, we estimate local surface geometry and albedo, then use photometric constraints for self-supervised adaptation to real-world sequences. After a brief self-adaptation step, the method runs at interactive frame rates.

PatchNets: Patch-Based Generalizable Deep Implicit 3D Shape Representations
ECCV, 2020
We introduce a mid-level patch-based implicit surface representation that generalizes across object categories. By learning patch-level signed distance functions in a canonical space, a model trained on a single ShapeNet category can represent detailed shapes from any other category using far less training data.
2015

Outdoor Human Motion Capture by Simultaneous Optimization of Pose and Camera Parameters
Eurographics, 2015
We present a markerless motion capture method for outdoor settings with hand-held or moving cameras. The approach simultaneously optimizes skeletal pose and camera parameters, extending performance capture beyond controlled studio environments.
2013

Capturing Relightable Human Performances under General Uncontrolled Illumination
Eurographics, 2013
We capture human performances that can be relit under novel illumination from multi-view video recorded under general, uncontrolled lighting. The method jointly estimates dynamic geometry, reflectance properties, and illumination, enabling realistic relighting in post-production.
Markerless Motion Capture of Multiple Characters Using Multiview Image Segmentation
IEEE PAMI, 2013
We present a markerless motion capture approach for simultaneously tracking multiple characters from multi-view video, enabling capture in scenes with close interactions where traditional methods fail due to occlusions.

2012

Coherent Spatiotemporal Filtering, Upsampling and Rendering of RGBZ Videos
Eurographics, 2012
We present a framework for coherent spatiotemporal processing of combined color and depth (RGBZ) video, producing temporally stable results suitable for free-viewpoint video and 3D display applications.

Feature-Based Multi-video Synchronization with Subframe Accuracy
DAGM, 2012
We present a feature-based approach to temporally synchronize multiple video streams with subframe accuracy, enabling the use of unsynchronized consumer cameras for multi-view reconstruction and motion capture.
2011

Video-based characters: creating new human performances from a multi-view video database
SIGGRAPH Asia, 2011
We synthesize novel human performances by recombining motion segments from a multi-view video database, creating character animations that were never actually performed while maintaining visual coherence.
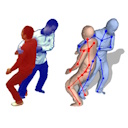
Markerless motion capture of interacting characters using multi-view image segmentation
CVPR, 2011
We propose a markerless capture method that handles closely interacting characters by using multi-view image segmentation to resolve inter-person occlusions, enabling robust motion capture in close-contact scenarios.

Fast articulated motion tracking using a sums of Gaussians body model
ICCV, 2011
We represent the human body as a sum of Gaussian density functions for fast articulated tracking. This smooth, differentiable representation enables efficient gradient-based optimization for pose estimation from multi-view silhouettes, achieving real-time performance for full-body markerless motion capture.
2010

Video-based reconstruction of animatable human characters
SIGGRAPH Asia, 2010
We present a complete pipeline for reconstructing fully animatable human characters from multi-view video, capturing skeletal motion and detailed surface deformations for rigged characters that can be reanimated with new motions.
Joint Estimation of Motion, Structure and Geometry from Stereo Sequences
ECCV, 2010
We propose a variational framework for jointly estimating dense optical flow, scene depth, and 3D surface geometry from stereo image sequences, exploiting their mutual dependencies for more accurate results.
2009

Template based shape processing
Saarland University, 2009 (PhD Thesis)
My PhD dissertation presents a unified framework for using template meshes to process and reconstruct 3D shapes, covering template deformation for point cloud fitting, performance capture from multi-view video, and volumetric shape editing.

Estimating body shape of dressed humans
Shape Modeling International, 2009
We address the problem of estimating the underlying body shape of a person wearing clothing, fitting a statistical body model to 3D scan data using shape priors to infer the body surface beneath garments.
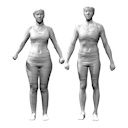
A Statistical Model of Human Pose and Body Shape
Eurographics, 2009
We present a statistical model that jointly captures the variability of human body shape and pose from a large corpus of 3D body scans, disentangling shape identity from pose-dependent deformations and providing a strong prior for body reconstruction.

Motion capture using joint skeleton tracking and surface estimation
IEEE CVPR, 2009
We propose a markerless motion capture method that jointly tracks the skeleton and estimates the body surface from multi-view video, coupling skeletal pose estimation with non-rigid surface deformation in a unified optimization.
2008

Performance capture from sparse multi-view video
ACM SIGGRAPH, 2008
We demonstrate high-quality performance capture from only a sparse set of cameras, significantly reducing the number required compared to prior dense capture setups. A template mesh is deformed to match multi-view silhouettes and sparse feature correspondences, recovering detailed non-rigid surface motion.
2007

Marker-less Deformable Mesh Tracking for Human Shape and Motion Capture
IEEE CVPR, 2007
One of the early methods for markerless human shape and motion capture using deformable mesh tracking from multi-view video, tracking a template mesh through a sequence by optimizing a deformation field matching observed silhouettes and image features.

A Volumetric Approach to Interactive Shape Editing
Technical Report, 2007
We propose a volumetric approach for interactive 3D shape editing where deformations are defined in the embedding volume, enabling intuitive modifications that preserve surface detail and topology during large-scale edits.

Rapid Animation of Laser-scanned Humans
IEEE VR, 2007
We present a method for quickly rigging and animating detailed 3D human models from laser scans, automatically fitting a skeleton and skinning weights to enable rapid creation of animatable characters.

Geodesics guided constrained texture deformation
Pacific Graphics, 2007
We introduce a method for deforming texture coordinates on 3D meshes guided by geodesic distances, enabling constrained texture mapping that follows the intrinsic surface geometry and preserves coherence during surface deformation.
2006

BSP Shapes
Shape Modeling and Applications, 2006
We present a shape representation based on binary space partitioning (BSP) trees that supports efficient Boolean operations and constructive solid geometry, providing compact hierarchical representation with fast inside/outside queries.

Incremental Raycasting of Piecewise Quadratic Surfaces on the GPU
Symposium on Interactive Raytracing, 2006
We introduce a GPU-based incremental raycasting algorithm for rendering piecewise quadratic surfaces at interactive rates, exploiting the mathematical structure of quadratic patches for efficient real-time rendering.

Template Deformation for Point Cloud Fitting
Point Based Graphics @ SIGGRAPH, 2006
We present a method for fitting a template mesh to unstructured point cloud data through non-rigid deformation, providing a robust way to obtain clean, connected meshes from noisy scan data.
2005

Visualization with stylized line primitives
IEEE Vis, 2005
We propose stylized line primitives for scientific visualization, enabling expressive non-photorealistic rendering of flow fields and vector data with controllable thickness, opacity, and curvature attributes.
2003

Direction Fields over Point-Sampled Geometry
WSCG, 2003
We define and compute smooth direction fields directly on point-sampled surfaces without requiring an explicit mesh, enabling texture synthesis and non-photorealistic rendering on point-based geometry.